今天这节课,我们来讲SEO技术审计,英文中的说法是Technical SEO Audit。这个概念大家可能有点陌生,你可以简单理解为它是SEO审计与IT相交的部分,也就是你需要一定的电脑知识才能掌握的部分。
首先,我们需要了解一个基本事实:SEO技术审计的难度是根据网站的具体情况而定的。
- 一些新网站,尤其是基于Shopify和Word Press这种系统建立起来的网站,不太可能出现明显的技术问题,做此类审计就会非常容易。
- 一些大网站,尤其是那些用不知名系统建立起来的网站,时间久了就容易出现各种各样的技术问题。你需要花费更多的时间和精力去发现并解决这类问题,如果解决不了,就会影响你的SEO效果。
SEO技术审计的考察内容非常多,一篇文章不足以全部覆盖。今天这节课,我们就讲一些最重要和最常见的技术性错误。细节性的东西我们会在谷歌SEO基础课程中展开介绍。
一、未妥善管理的404错误
在电商网站中,我经常看到这类404错误。当一个站长删除了某些产品,但是保留了指向这些产品的站内链接的时候,就会出现404错误页。
404错误对网站SEO的负面影响主要在于它会浪费搜索引擎的索引预算。我们知道,谷歌蜘蛛每一次访问你网站的Crawl Budget是有限的,如果它频频访问不存在的页面,就会影响新网页的索取成功率。
其次,404错误页还会有以下负面影响:
- 它们会浪费流量(站内的流量和来自搜索引擎的流量),造成不良的用户体验;
- 如果有外链指向404错误页,外链的Link Juicy就会被浪费掉;
- 如果有内链指向404错误页,内链的Link Juicy也会被浪费掉;
- 如果你曾经分享到Pinterest之类的社交媒体,访客也到达不了你希望的页面;
最有效的解决方式,就是使用301重定向,把删除的旧网址指向你认为合适的相关页面。这有利于留住你网站的链接汁,并且访客也不会被404错误页面挡住去路。
如何发现404错误页面?
我们有两个方式:
- 使用蜘蛛模拟器Screaming Frog爬网,可以发现全部的404错误页。
- 使用Google Search Console报表(Crawl->Crawl Errors)。
如何处理发现的404错误页面?
- 在网站内为404错误页面寻找一个内容相关的有效页面;
- 使用301重定向,把404页面指向你所选定的相关页面。
二、网站迁移
这里所说的网站迁移包含三种情况:
- 从网站abc.com迁移到xyz.com
- 安装SSL证书,使http://www.abc.com显示为https://www.abc.com
- 移除www,使https://www.abc.com显示为https://abc.com
网站迁移过程中常见的SEO技术错误:
- 使用302重定向,而不是301重定向。302是临时性的,301才是永久性的,很多人会搞不清区别。
- 忘记把http版本的网址重定向到https版本,这样导致网站上有两个不同版本的网页同时存在,比如http://abc.com和https://abc.com都可以访问你的网页。这是网址规范化的常见错误,我们要确保同样的内容,在网站上只有一个显示的网址。
- 使用插件301重定向,而不是在服务器端重定向。插件重定向的好处是操作简便,但是如果你的根网址换了,它不会识别。比如说,我们以前已经把http://abc.com/page-1-xxx通过站内插件重定向到http://abc.com/page-1了。现在你的域名变为了http://xyz.com,那么原来的301重定向都会停止工作。
- 老域名的标签忘记更新。比如canonical tag, NOINDEX tag,很多网站会使用这些标签来向搜索引擎传递信号,更换到新网址的时候需要替换掉。
- 无意中形成了redirect链条。比如说,我们曾经把http://www.abc.com重定向到http://abc.com了,现在我更换网址为xyz.com了,那么有些人可能就会在无意中形成这样的301重定向链条:http://www.abc.com->http://abc.com->https://abc.com->https://xyz.com。301重定向虽然会传递权重,但是这个传递过程是逐级递减的,正确的做法是http://www.abc.com->https://xyz.com,一步到位。
- 网站同时存在www和non www版本,忘记在.htaccess中指定唯一版本。这也会造成重复内容被索引,对SEO不利。
如何发现网站迁移过程中的SEO技术错误:
和之前的一样,使用Screaming Frog可以轻松找出来。
如何处理网站迁移过程中导致的错误问题:
更新你的robots.txt和.htaccess文件即可。看不懂这两个文件的意思可以找服务器公司解决,一般售后都会提供此类服务。
三、网站加载速度
这个问题我们讲过多次了,大家可以从这篇文章详细了解下:https://seozdm.com/website-speed-tools/
四、没有优化手机用户体验
谷歌官方已经明确提出了移动优先。这意味着,谷歌蜘蛛首先会访问你网站的移动版本。如果你的网站给移动用户的体验很差,那么将会极大地影响你的网站排名——不管你的网站在桌面端看起来有多么吸引人。
你所需要做的就是确保网站对移动设备是友好的(WordPress的默认功能),也就是我们所说的响应式页面。
如何判断网站对移动设备是否友好?
- 使用谷歌的移动设备适应性测试,检查下谷歌对你网站移动友好的评分。如果可以得到类似这样的结果,就表明还不错。


- 确保robots.txt中没有屏蔽Googlebot Smartphone
- 使用不同屏幕尺寸的移动设备访问网站,包括苹果和安卓系统。不只是手机要测试,还要用平板测试(横屏和竖屏都要测试)。
如何解决这类错误?
- 我们不需要为移动设备专门制作一个子域名。过去的经验是提供一个m.yourdomain.com版本的网址专门给移动用户访问。在当今时代,这是错误的,它会占用更多的抓取预算,也会有很多重复性内容。
- 雇佣专业的开发人员制作响应式主题,光靠插件来实现响应式页面是不行的。
- 避免使用Flash,如果一定要实现动态效果,可以考虑用Google web designer, 它可以用HTML5来实现类似flash的动态效果。
五、XML地图问题
XML地图的作用是列出网站上的所有页面,以便搜索引擎来爬取和索引。
XML通常包含以下内容:
- 网址清单
- 网页最后更新的日期
- 更新的频率
- 该网址相对于其他网址的优先级(谷歌官方明确否定这个的作用,但是貌似对百度有效)
有些时候,XML地图作用是显著的,比如说:
- 网站上有些页面没有站内链接,用浏览器无法直接找到;
- 站长使用了太多Ajax,Silverlight和Flash内容,谷歌不索引这类内容;
- 网站内容太多,蜘蛛程序无法全部爬取;
如何检查XML里面的错误?
- 首先,你需要确保已经把XML提交给了Google Search Console,Bing和Yahoo的网站管理员工具;
- 其次,在Search Console中查看Crawl->Sitemaps->Sitemap Errors;
- 访问网站的日志,查看站点地图最后被搜索引擎机器人访问的时间(找服务器公司客服解决);
如何解决XML错误?
- 最直接的方式是查看Google Search Console,谷歌会告诉你网站存在哪些问题;
- 如果使用了SEO插件(比如Yoast),你需要确保插件更新到最新版本,和你当前使用的Word Press系统兼容;
- 如果你发现网站一直没有被索引,而你确信XML没有出现问题,那么你可以考虑检查服务器日志(你需要向服务器公司索取),然后用服务器日志分析工具(比如SEOlyzer), 它会告诉你搜索引擎蜘蛛访问你Sitemap的频率;也可以直接咨询服务器公司,让他们帮你查看。
六、URL结构问题
对于大多数网站来说,尤其是不懂SEO的人来说,忽视网站的URL结构是最常见的技术性错误之一。一个糟糕的网站结构不利于用户(也不利于搜索引擎)访问你的网站,这对SEO的影响是负面的。
糟糕的URL结构有哪些特征?
- 网站结构组织混乱;
- 没有合理布局目录和子目录;
- URL中包含有特殊字符,大写字母,空格等;
如何找出XML中的错误?
- 如果网站中有404,302之类的错误代码,那么要确保这些网址已经从XML中移除;
- 使用Screamfrog爬网,对比两者之间的网址差异;
- 从Google Search Console中去查看爬网错误提示;
如何解决XML中的错误?
- 建站之前规划好网站的结构,我通常建议大家手绘结构图(也可以用思维导图),把父级目录和子目录之间的关系想清楚以后再上传网站;
- 确保网站上所有内容都合理安排在正确的目录和子目录之下;
- 确保URL路径容易阅读,容易理解,避免使用无意义字符;
- 如果网站不同页面都在争取同一个关键词的排名,那么你要么把他们合并,要么删除其中之一(然后采用301转向);
- 尽量减少网站的深度,如果使用了3级以上的目录结构,那么网站就过于错综复杂,不利于用户和搜索引擎访问;
七、robots.txt处理不当带来的麻烦
robots.txt的作用是告诉搜索引擎该如何访问你的网站,如果处理不当,它将妨碍搜索引擎索引你的网站内容。
Biu叔学堂曾有粉丝在微信群里面反应谷歌不索引自己的网站,我们后来发现是robots.txt阻止了谷歌的访问。国内有些建站公司喜欢在网站未完善之前阻止搜索引擎访问,他们认为这会向用户展示一个未完成的网站,以为对SEO不利。对这类说法,Biu叔一直是不以为然的,我从注册域名开始就不阻止谷歌访问网站内容。
如何找出Robots.txt中存在的问题?
- 检查网站的访问数据,如果从Google Analytics中发现网站流量明显下降,有可能是robots.txt阻止了搜索引擎访问;
- 检查Google Search Console报表,使用Robots.txt tester工具(详情请看https://support.google.com/webmasters/answer/6062598?hl=en)
如何解决Robots.txt中的错误问题?
- 按照robots.txt Tester的提示操作;
- 确保你不希望被谷歌索引的目录和文件都在robots.txt中有注明;
八、网站包含太多薄内容
有很多人喜欢定期添加新网页,他们认为这样“可以提高网站权重”,从而获得更好的谷歌排名。这是非常错误的操作方式,谷歌喜欢的是有价值的,有深度的内容。质量永远比数量重要。
换句话说,网站如果拥有太多的薄内容页面(正文少于500字都算是薄内容),会影响自己网站的谷歌排名。如果薄内容太多,谷歌爬取网站的频率会降低,索引率也会降低,你的流量自然就会减少。
简单地说,你不应该为每一个目标关键词设定一个内容页面,你应该为尽可能多的目标关键词设定一个内容丰富的页面。这将有利于你创建有深度的内容,从而获得更好的谷歌排名。
如何找出网站的薄内容页面?
- 用蜘蛛程序爬取网站,检查少于500字的网页;
- 检查GSC里面的消息(GSC->Messages);
- 某些针对特定关键词制作的内容页面没有排名,需要特别检查;
- 从Google 分析工具中查看跳出率,跳出率特别高的网页可能是薄内容页面;
如何解决薄内容页面所带来的不利影响?
- 如果你的网站有很多文章都是针对含义相同的关键词写的,那么可以考虑把这些文章的内容合并;
- 考虑为网站添加文本以外的的内容形式,比如说音频、视频、信息图等。如果自己不太会弄这类东西,可以考虑外包。除了大家熟悉的淘宝,常见的外包平台有Upwork, Fiverr和PeoplePerHour。
- 把你的用户放在首位,他们需要什么?你的主要目标就是创建可以满足用户需求的内容。
九、网站包含太多的不相干页面
除了我们上面说过的薄内容页面,我们还需要检查网站的“不相关页面”。所谓的不相关页面就是对网站用户没有价值的页面,或者说网站用户不想看的页面。很多时候,不相关页面没有特定的关键词排名目标,甚至就是站长的自嗨行为,对于访客来说,这些内容很无聊。不相干页面也会给网站拖后腿。
对于很多新建立的网站而言,减少甚至删除不相关页面是很重要的。与权威网站相比,谷歌访问新站的频率较低。这意味着我们要尽可能为它提供最好的内容,以便于提高我们网站的可信度和权威性,这有利于让谷歌给我们分配更多的索引预算。
如何找出网站的不相关页面?
- 仔细审查自己的内容策略。确保每一篇文章都能够为用户带来价值,不要为了发布新文章而发布新文章。形式主义害死人。
- 检查用户的参与度,一些参与度为零的文章(无人评论或者无人分享的文章),可能是不受用户欢迎的内容。
发现不相干页面怎么处理?
- 最简单的方式是删除他们,然后301指向一个你认为内容相似并且有实际意义的页面(比如说已经有谷歌排名或者有自然搜索流量的页面);
- 如果实在是需要保留这些页面,那也可以把他们加入robots.txt,阻止谷歌去索引他们。这样,我们可以确保谷歌可以集中力量优先处理我们的优质内容。
十、Canonical Tag的不当使用
当你网站上有两个内容相似的页面,而你又不想删除任意一个的时候,你需要使用Canonical标签告诉谷歌,哪一个页面应该优先出现在搜索结果页面之中。Canonical标签的源代码表现为:”rel=canonical”。
如果我们使用Word Press,那么Yoast可以帮助我们执行这一操作。
但是,Canonical 标签经常容易被错误使用。常见的错误操作有:
- 用于两个内容明显不相关的网页;
- 指向一个已经删除的网页,即我们之前所说的404页面;
- 整个网站没有一个Canonical 标签,该用的时候不用;
Canonical标签的错误使用有时候会带来很多问题,尤其是当我们在一些重要网页上使用的时候,你很可能会流失掉许多原本可以获得的流量,相当于是自废武功。
如何找出网站哪些页面用了Canonical标签?
最简单的方式就是使用Screaming Frog工具检查下网站的全部页面。
Canonical标签用错了怎么办?
- 人工检查,看哪些网页的标签指向了错误的页面;
- 做一个内容审计,找出网站上所有内容相似的页面,看看其中是否有一些需要添加canonical标签。
十一、robots标签的错误使用
robots标签的作用和robots.txt差不多,都是为了告诉搜索引擎是否该索引网页内容,它们中的细微差别我们这里不做过多阐述。robots标签存在于网页html源代码<head></head>中,看起来是这个样子的:

如果使用不当(最常见的错误就是过多使用robots标签),也可能导致优化过的页面怎么都排不起来。有关robots标签的详细描述,请参考官方网站:https://developers.google.com/search/reference/robots_meta_tag
如何查找这类robots标签错误:
- 用浏览器查看网页源代码,看是否包含了过多的robot标签;
- 注意区分nofollow链接属性和nofollow robots标签。如果网页中包含有<meta name=”robots” content=”nofollow”>,那么该网页中所有链接都等同于带上了nofollow属性。
如何改正被错误使用的robots标签?
- 如果你确定需要使用robots标签,那么Yoast可以帮助你实现这个目标,具体操作请看:https://yoast.com/wordpress/plugins/seo/yoast-seo-robots-meta-configuration/
- 尽量在robots.txt中集中管理,而不是在单个页面中分别添加robots标签。
十二、未合理安排Craw Budget
由于信息大爆炸,哪怕是对于谷歌这样的搜索引擎巨头来说,要索引全世界的网页也是有困难的。为了提高效率,谷歌为每一个网站分配了不同的爬网预算。在理想状态下,我们希望谷歌分配的爬网预算足够覆盖网站的所有页面,这样才有利于网站的排名;但是现实生活中,谷歌分配给每一个网站的预算都不是无限的。权威网站能够分配到的Craw Budget通常高于普通网站。用谷歌自己的话来说,它们要分配爬网的优先级,以便决定什么时候来爬取你的网站,每次爬网分配多少资源。
如何找出这些错误?
- 最有效的方式,是从google search console中检查爬网状态,也就是Crawl下面的Crawl Stats。
- 查看服务器日志,查看谷歌蜘蛛把时间花费在哪些页面上了。这些信息可以帮助你找出谷歌是否在爬取你的重要页面,除了我们之前介绍的SEOlyzer,你还可以使用botify来理解服务器日志。
- 询问服务器客服,谷歌最近的爬网状态。
如何解决爬网预算未合理安排所带来的后果?
- 阻止谷歌爬取一些不重要的网页;
- 减少301重定向的链条环节;
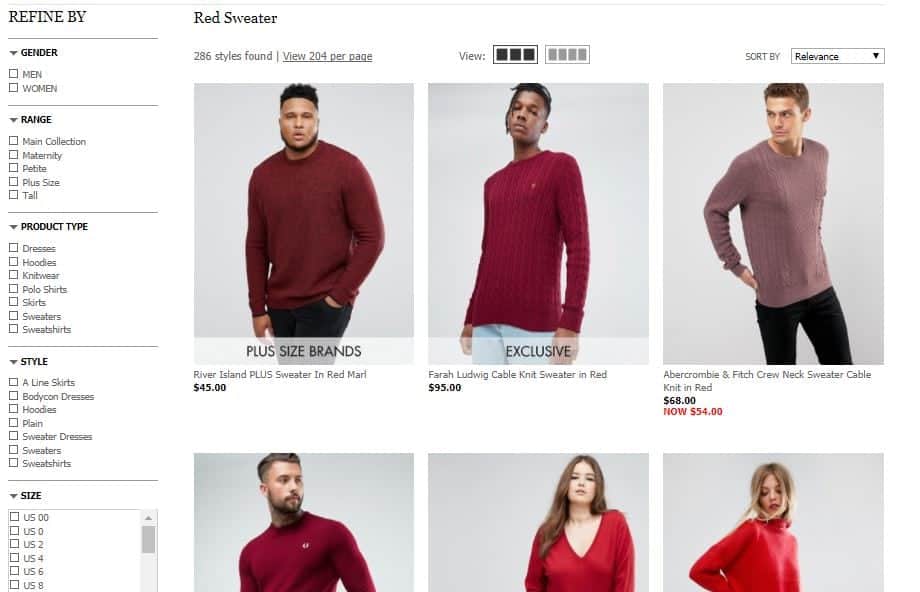
- 如果是电商网站,注意屏蔽一些产品参数标签所带来的内容重复性网址,也就是英文中所说的faceted URLs;下图中左边部分是电商网站常见的导航栏目,处理不当的话很容易带来负面影响。
十三、未合理利用内链来传递“链接汁”
内链可以帮助网站的链接汁在不同页面之中传递,也可以用于引导用户到达你期望的转化页面。内链可以促进部分页面获得更好的关键词排名,是因为它可以把整个网站的权重向重要页面进行倾斜,或者说,内链可以把权重聚拢在某些特别重要的页面上(国外流行的权重雕琢的核心思想就在于此)。有些人认为内链可以增加网站的权重,这种说法是错误的。合理安排内链的使用,是Biu叔三大猜想之一的“谷歌微调”的理论来源之一(其他两项是谷歌初选和众星拱月)。Biu叔认为,这是一种类似于外科手术式的精确操作,把网站所有的权重聚焦在一些重要的页面,不要让次要页面争夺网站的整体权重。这对于谷歌排名来说,有时候可以起到事半功倍的效果。
如何找出未合理分配的内链?
- 对于那些重要的网页(你希望获得更好谷歌排名的网页),检查下有没有给他们合理安排内链?
- 使用Screaming Frog可以帮你统计内链情况;
- 如果使用了某些自动添加nofollow属性的插件,你要注意那些内链是不是也带了nofollow属性。
如何解决内链安排失误所带来的问题?
- 对于重要的页面,你需要给他们安排多一些内链,以便它们获得更好的排名;
- 对于不重要的页面(比如contact us),你需要减少在文章中使用内链的频率,或者在内链中加入nofollow属性;
- 不用过度使用内链,也不要过度使用关键词作为内链的锚文本,只有在确定必要的前提下才使用内链;
- 如果重要的页面带了Nofollow,则要删除掉;
十四、结构化数据
我们之前在介绍搜索引擎结果页面特色的时候,已经知道现在谷歌会展示不一样的效果。如果你也希望打扮一下自己网站在搜索结果页面的出场方式,你需要掌握的就是结构化数据。我们需要注意的两点:
- 要不要使用结构化数据,决定权在站长;但是能不能表现出不一样的结果,决定权在谷歌;换句话说,你哪怕用了结构化数据,谷歌不一定就会在结果页面展示出来,要看运气。
- 结构化数据改变的是在搜索引擎结果页面的表现形式,并不是直接的排名因素。不过它也许可以通过提高点击率间接影响谷歌排名。
我们能够使用的结构化数据主要有:
- Map Data
- Review Data
- Rich snippet data
- Product data
- Book Reviews
- FAQ
- etc
如何找出结构化数据被错误使用的网页?
- 使用Google Search Console, 通过Search Appearance->Structured Data来检查Schema是否被谷歌提取,以及提取过程中是否出现错误代码;
- 使用谷歌的结构化数据标记辅助工具, 输入网址即可直接判断。
如何在网站中使用结构化数据?
- 如果你使用的是Word Press,那么可以尝试这两个插件:All in One Schema 和 RichSnippets
- 如果你不是用Word Press,那就要找程序员自己开发了。
以上就是与IT有关的谷歌SEO技术性的东西,如果这些东西你都掌握了,那么恭喜你,最大的一块石头被你搬走了。对于绝大多数人来说,掌握这些SEO技术已经足够,国内大多数的SEO博客都做不到这些。当然,如果你要进入更高的阶段,那么灵活使用Google Sheet就是你下一步需要掌握的高级技能,那是SEO公司主管才需要掌握的能力。



